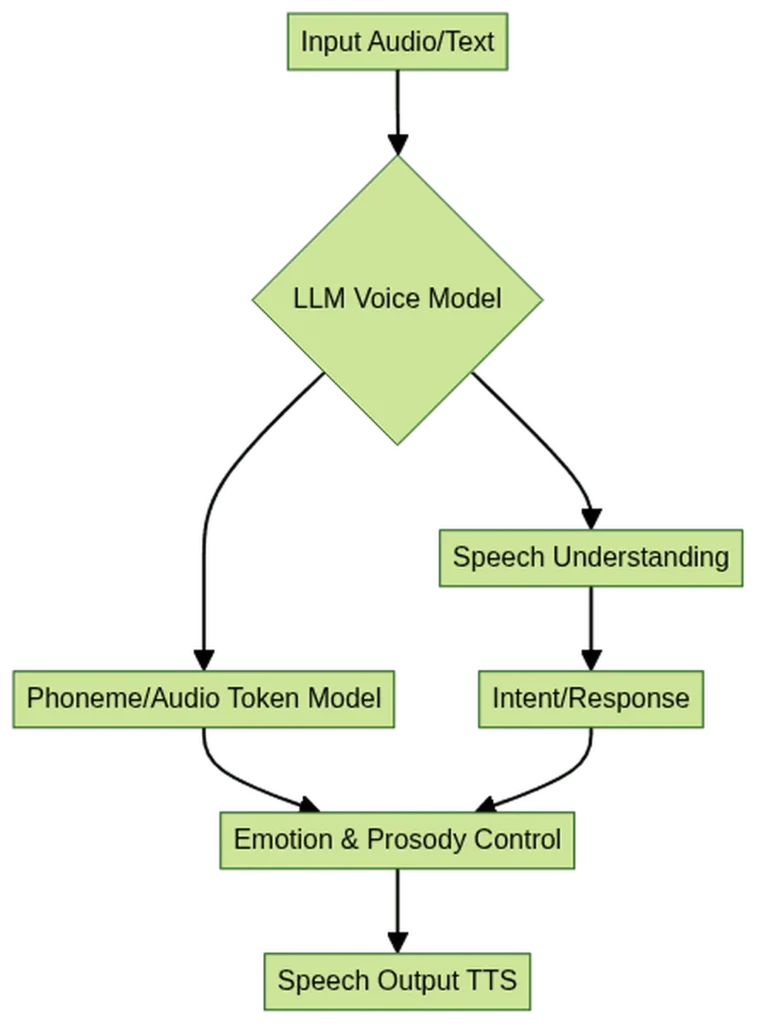
In the rapidly evolving landscape of audio and language technology, the human voice remains a rich yet underutilized resource. A recent study by researchers Mingyue Huo, Wei-Cheng Tseng, Yiwen Shao, Hao Zhang, and Dong Yu aims to bridge this gap by developing a general-purpose voice encoder that effectively captures both identity and paralinguistic cues. Their work, centered around the creation of Auden-Voice, represents a significant step forward in the quest to build more nuanced and comprehensive audio-language models (LALMs).
The human voice is a complex instrument, encoding not just linguistic content but also a wealth of information about the speaker’s identity, emotions, and intent. Despite this, existing voice encoders in LALMs often fall short of fully leveraging these nuances. The researchers set out to address this limitation by exploring different training methodologies to create a voice encoder that balances the representation of both identity and paralinguistic cues.
Through a comprehensive evaluation, the team discovered that multi-task training yielded the most balanced representations. This approach involves training the model on multiple related tasks simultaneously, allowing it to learn a more robust and versatile set of features. In contrast, contrastive language-audio pretraining (CLAP), while effective for improving retrieval tasks, did not significantly enhance the model’s understanding of paralinguistic cues.
The culmination of this research is Auden-Voice, a voice encoder that demonstrates strong performance across a variety of tasks. When integrated with large language models (LLMs), Auden-Voice shows promise in enhancing the overall capability of these models to understand and interpret human voice. This integration could have far-reaching implications for applications ranging from virtual assistants and customer service chatbots to advanced transcription services and beyond.
The researchers plan to release the code and training recipes with the audio understanding toolkit Auden, making their work accessible to the broader research community. This open-source approach is expected to accelerate further advancements in the field, as other researchers and developers can build upon and refine the Auden-Voice encoder.
The development of Auden-Voice highlights the importance of balancing different aspects of voice representation in audio-language models. By capturing nuanced voice cues, the encoder not only improves the accuracy and effectiveness of speech and language understanding systems but also paves the way for more natural and intuitive human-machine interactions. As the technology continues to evolve, we can expect to see even more sophisticated applications that harness the full potential of the human voice.

