In the rapidly evolving field of video understanding, researchers have been making strides in developing systems that can accurately retrieve specific temporal segments from untrimmed videos based on natural language queries. This task, known as Video Moment Retrieval, has seen advancements through both traditional techniques and the use of Multimodal Large Language Models (MLLM). However, existing methods often fall short due to their reliance on coarse temporal understanding and a single visual modality, which can hinder performance, especially in complex videos.
To tackle these limitations, a team of researchers has introduced SMART, an innovative MLLM-based framework designed to enhance the precision of video moment retrieval. SMART, which stands for Shot-aware Multimodal Audio-enhanced Retrieval of Temporal Segments, integrates audio cues and leverages shot-level temporal structure to achieve more accurate and nuanced results.
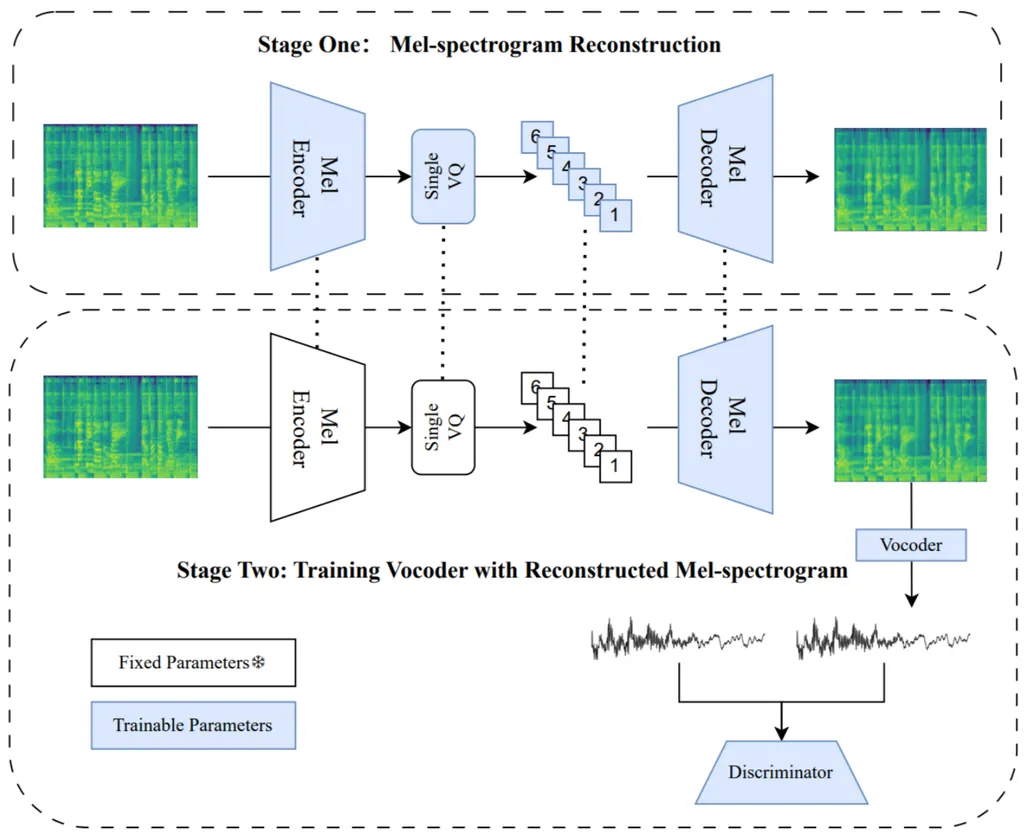
One of the key features of SMART is its ability to enrich multimodal representations by combining audio and visual features. This integration allows the system to capture a more comprehensive understanding of the video content. Additionally, SMART employs Shot-aware Token Compression, a technique that selectively retains high-information tokens within each shot. This process reduces redundancy and preserves fine-grained temporal details, leading to more precise moment retrieval.
The researchers have also refined the prompt design to better utilize audio-visual cues, further enhancing the system’s performance. Evaluations on benchmark datasets such as Charades-STA and QVHighlights have demonstrated significant improvements over state-of-the-art methods. Specifically, SMART achieved a 1.61% increase in R1@0.5 and a 2.59% gain in R1@0.7 on the Charades-STA dataset, highlighting its effectiveness in accurately localizing temporal segments within videos.
The implications of SMART’s advancements are far-reaching, particularly in the realm of audio and music production. As video content becomes increasingly complex and multimodal, the ability to accurately retrieve specific moments based on natural language queries becomes crucial. For audio professionals, this technology can streamline the editing process, allowing for more efficient and precise manipulation of video and audio segments. Furthermore, the integration of audio cues in SMART’s framework opens up new possibilities for enhancing the synchronization between visual and auditory elements in multimedia projects.
In conclusion, the introduction of SMART represents a significant step forward in the field of video moment retrieval. By leveraging shot-level temporal structure and integrating audio cues, this innovative framework offers a more nuanced and accurate approach to localizing temporal segments within videos. The practical applications of SMART extend beyond video understanding, promising to revolutionize the way audio and music professionals work with multimedia content. As the technology continues to evolve, we can expect to see even greater advancements in the integration of audio and visual elements, paving the way for more immersive and dynamic multimedia experiences.