In the rapidly evolving landscape of music technology, the quest for real-time, low-latency music source separation has taken a significant leap forward. A team of researchers, including Junyu Wu, Jie Liu, Tianrui Pan, Jie Tang, and Gangshan Wu, has introduced a groundbreaking model called Real-Time Single-Path TFC-TDF UNET (RT-STT). This innovation is poised to revolutionize various applications, from hearing aids to live performances, by addressing the critical need for efficient, real-time audio processing.
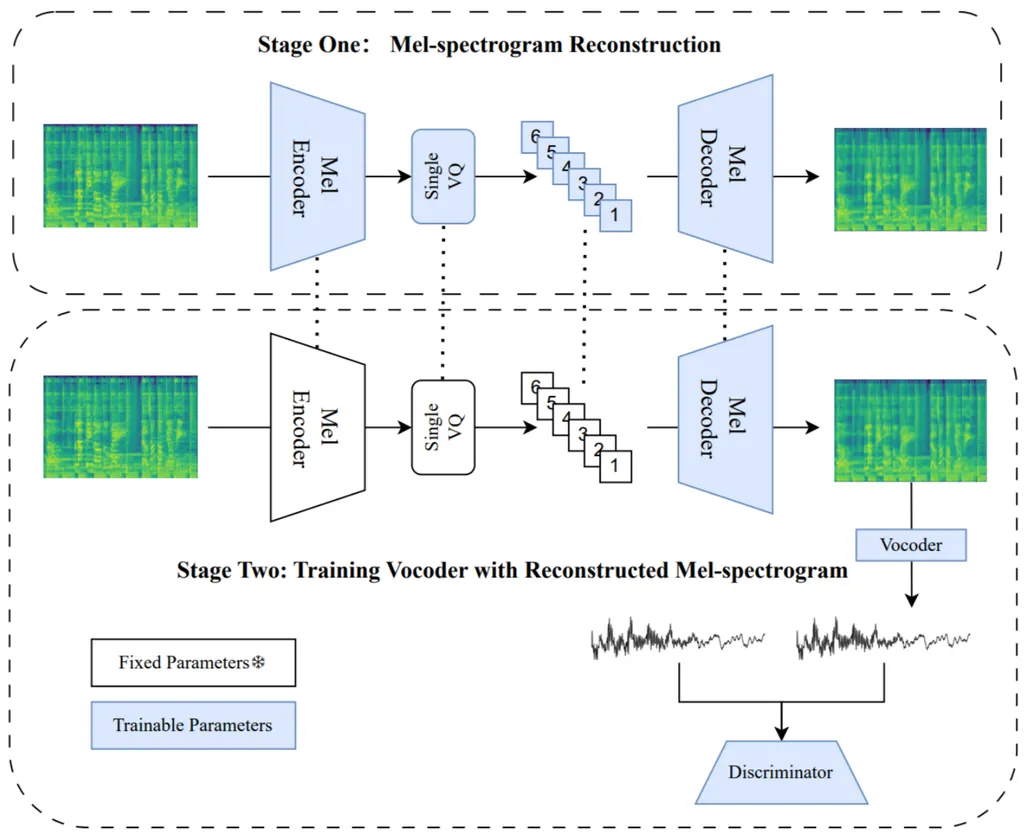
The RT-STT model is a lightweight, yet powerful, solution that builds upon the Dual-Path TFC-TDF UNET (DTTNet). The researchers have ingeniously incorporated a feature fusion technique based on channel expansion, which enhances the model’s performance without significantly increasing its computational load. This is a notable advancement, as previous efforts in the field of deep learning for music demixing have often focused on developing larger, more resource-intensive models. The RT-STT’s lightweight design makes it more versatile and applicable in scenarios where computational resources are limited.
One of the key findings of this research is the superiority of single-path modeling over dual-path modeling in real-time applications. By streamlining the model’s architecture, the researchers have achieved shorter inference times and fewer parameters, all while maintaining high performance. This is a significant breakthrough, as it challenges the prevailing trend in the industry and opens up new possibilities for real-time audio processing.
Furthermore, the researchers have explored the method of quantization to further reduce inference time. Quantization is a technique that reduces the precision of the numerical values used in the model, which can significantly speed up computations. By carefully applying this technique, the researchers have been able to enhance the model’s efficiency without compromising its accuracy.
The implications of this research are far-reaching. In the realm of live performances, real-time, low-latency music source separation can enable musicians to remix and manipulate their audio streams on the fly, opening up new avenues for creativity and expression. In the field of hearing aids, it can improve the clarity and intelligibility of speech in noisy environments, greatly enhancing the quality of life for users. And in the broader context of audio stream remixing, it can facilitate the creation of personalized, adaptive audio experiences.
In conclusion, the RT-STT model represents a significant step forward in the field of real-time, low-latency music source separation. Its lightweight design, superior performance, and versatility make it a powerful tool for a wide range of applications. As the researchers continue to refine and improve this model, we can expect to see even more exciting developments in the world of music technology.