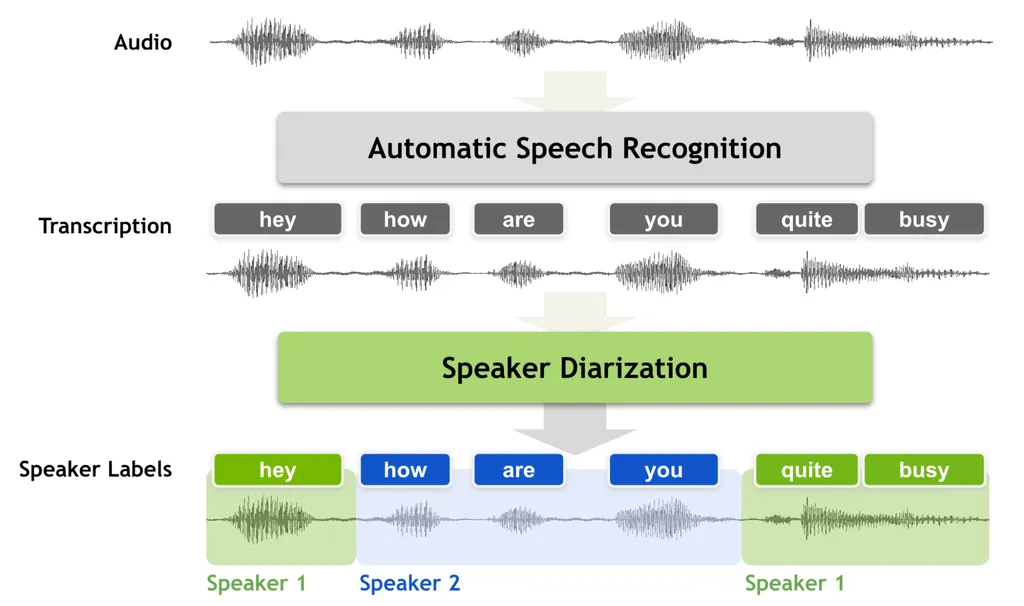
In the ever-evolving landscape of audio technology, researchers are constantly pushing the boundaries of what’s possible. A recent study has introduced a novel approach to multi-channel neural speaker diarization that could significantly enhance the way we process and understand audio data. The research, led by Jiangyu Han and colleagues from various institutions, focuses on making self-supervised models like WavLM more effective in multi-channel scenarios.
Traditionally, models like WavLM are pre-trained on single-channel recordings. While they perform well in such settings, their effectiveness diminishes when applied to multi-channel environments. Current systems often use a method called DOVER-Lap to combine outputs from individual channels, but this approach is computationally intensive and doesn’t fully utilize spatial information. The researchers aimed to address these limitations by introducing a lightweight method to make pre-trained WavLM models spatially aware.
Their approach involves inserting channel communication modules into the early layers of the WavLM model. This modification allows the model to better handle multi-channel inputs, regardless of the number of microphone channels or array topologies. By making the model spatially aware, the researchers can leverage spatial attention weights to fuse multi-channel speaker embeddings more effectively.
The team built on DiariZen, a pipeline that combines WavLM-based local end-to-end neural diarization with speaker embedding clustering. Their new method demonstrates consistent improvements over single-channel baselines and outperforms the DOVER-Lap approach in terms of both performance and efficiency. The researchers evaluated their method on five public datasets, providing robust evidence of its effectiveness.
One of the most exciting aspects of this research is its potential impact on the music and audio industry. As we move towards more immersive audio experiences, the ability to accurately diarize speakers in multi-channel environments becomes increasingly important. This technology could enhance applications ranging from virtual reality and augmented reality to advanced audio production and post-production processes.
Moreover, the researchers have made their source code publicly available, fostering further innovation and collaboration within the community. This open-access approach encourages other researchers and developers to build upon their work, potentially leading to even more advancements in the field.
In summary, this research represents a significant step forward in the realm of multi-channel neural speaker diarization. By making self-supervised models spatially aware, the researchers have opened up new possibilities for enhancing audio processing technologies. As the industry continues to evolve, such innovations will be crucial in shaping the future of music and audio technology.

