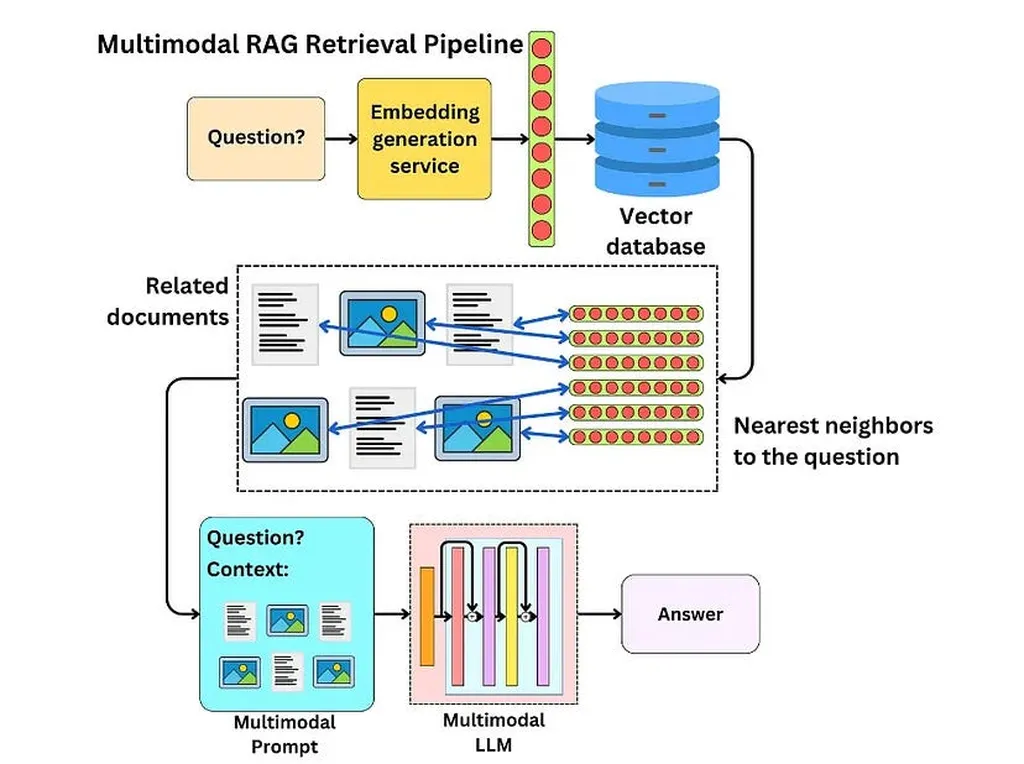
In the rapidly evolving world of AI, the ability to handle and process different types of data, or modalities, is becoming increasingly important. This is where multimodal AI systems come into play, and a crucial aspect of these systems is chunking strategies. A recent survey, conducted by Shashanka B R, Mohith Charan R, and Seema Banu F, aims to consolidate the landscape of these strategies, providing a technical foundation for developing more effective and efficient multimodal AI systems.
The survey provides a comprehensive taxonomy and technical analysis of chunking strategies tailored for each modality: text, images, audio, video, and cross-modal data. For text, classical and modern approaches such as fixed-size token windowing and recursive text splitting are examined. For images, the focus is on object-centric visual chunking. In the audio domain, silence-based audio segmentation is explored, while scene detection is the key strategy for video data.
Each approach is analyzed in terms of its underlying methodology, supporting tools (e.g., LangChain, Detectron2, PySceneDetect), benefits, and challenges, particularly those related to granularity-context trade-offs and multimodal alignment. The survey also delves into emerging cross-modal chunking strategies that aim to preserve alignment and semantic consistency across disparate data types.
The researchers provide comparative insights and highlight open problems such as asynchronous information density and noisy alignment signals. They also identify opportunities for future research in adaptive, learning-based, and task-specific chunking. This survey is a significant step towards innovations in robust chunking pipelines that scale with modality complexity, enhance processing accuracy, and improve generative coherence in real-world applications.

