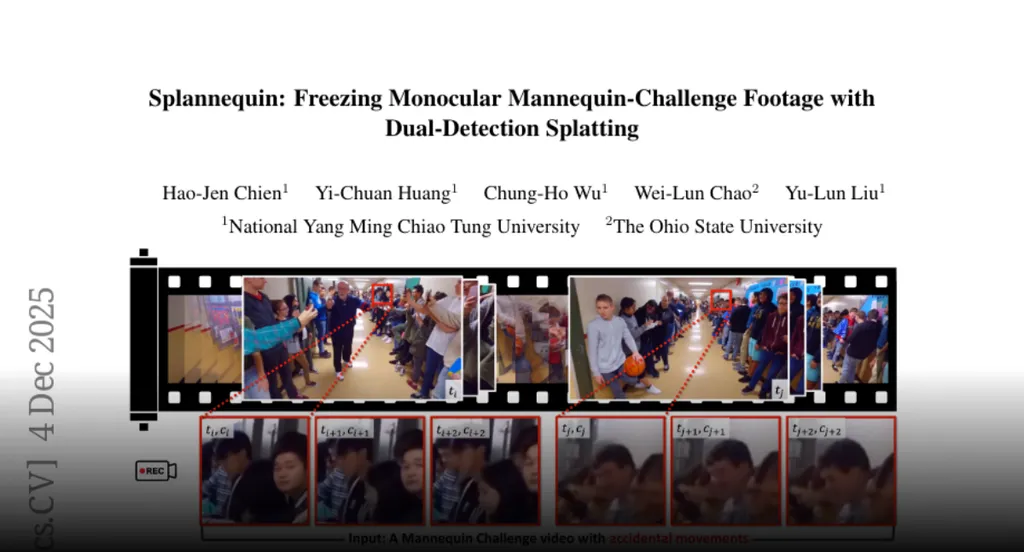
In the world of video technology, there’s a unique challenge that researchers are tackling: creating high-fidelity frozen 3D scenes from monocular Mannequin-Challenge (MC) videos. This is different from the standard dynamic scene reconstruction because the focus isn’t on modeling motion, but rather on creating a frozen scene while preserving subtle dynamics for user-controlled instant selection.
A novel approach to this problem is the application of dynamic Gaussian splatting. This method models the scene dynamically, retaining nearby temporal variation, and renders a static scene by fixing the model’s time parameter. However, this usage can introduce artifacts like ghosting and blur for Gaussians that become unobserved or occluded at weakly supervised timestamps due to monocular capture with sparse temporal supervision.
To address this, researchers have proposed Splannequin, an architecture-agnostic regularization that detects two states of Gaussian primitives: hidden and defective. It applies temporal anchoring, where hidden states are anchored to their recent well-observed past states, and defective states are anchored to future states with stronger supervision. This method integrates into existing dynamic Gaussian pipelines via simple loss terms, requires no architectural changes, and adds zero inference overhead.
The result is a markedly improved visual quality, enabling high-fidelity, user-selectable frozen-time renderings. The effectiveness of this method was validated by a 96% user preference in tests. This research, conducted by Hao-Jen Chien, Yi-Chuan Huang, Chung-Ho Wu, Wei-Lun Chao, and Yu-Lun Liu, represents a significant step forward in the field of video technology and dynamic scene reconstruction.

