In a significant leap forward for audio technology, researchers have introduced MelCap, a unified neural codec that promises high-fidelity audio compression for speech, music, and general sound. This innovative approach addresses the limitations of existing methods, which either focus solely on speech or use multiple quantizers that complicate downstream tasks.
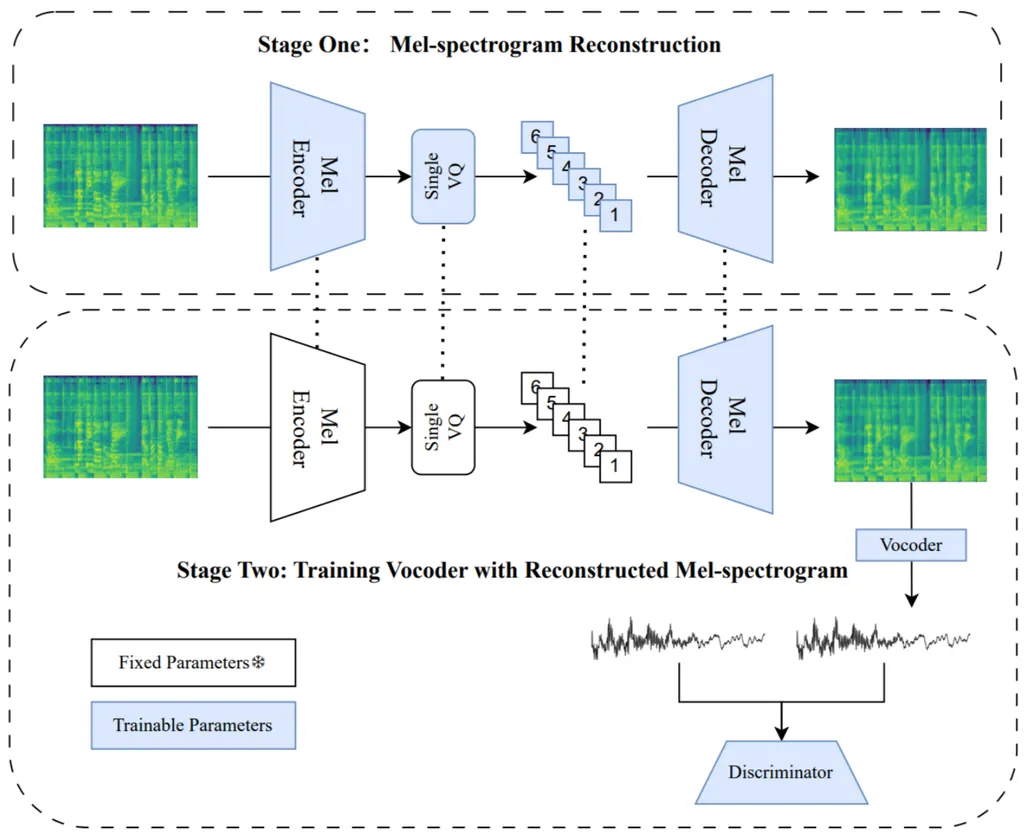
MelCap stands out by employing a single, versatile codebook to handle a wide range of audio types. The researchers achieved this by breaking down audio reconstruction into two distinct stages. In the first stage, the audio signal is transformed into mel-spectrograms, which are then compressed and quantized into compact single tokens using a 2D tokenizer. To ensure high-quality reconstruction, a perceptual loss is applied to minimize over-smoothing artifacts that can occur in spectrogram reconstruction. This stage effectively captures the essential acoustic details of the audio.
In the second stage, a Vocoder takes the mel discrete tokens and recovers the original waveforms in a single forward pass, enabling real-time decoding. This efficient process allows MelCap to achieve performance comparable to mainstream multi-codebook methods while maintaining the computational simplicity of a single-codebook design.
The researchers conducted both objective and subjective evaluations to validate the effectiveness of MelCap. The results demonstrated that MelCap achieves quality comparable to state-of-the-art multi-codebook codecs, making it a promising tool for high-fidelity audio compression. Its unified approach not only simplifies the compression process but also provides an effective representation for downstream tasks, such as audio editing, enhancement, and synthesis.
For music and audio production, MelCap offers practical applications that could revolutionize the industry. Its ability to compress high-fidelity audio efficiently means that musicians, producers, and engineers can work with high-quality audio files without the burden of large file sizes. This is particularly beneficial for streaming services, where bandwidth and storage are critical concerns. Additionally, the unified codebook design simplifies the integration of audio processing tools, making it easier to apply effects, edits, and enhancements to audio files.
Furthermore, MelCap’s real-time decoding capability opens up new possibilities for live performances and interactive audio applications. Musicians and producers can manipulate audio in real-time, enabling dynamic and immersive experiences. The potential for real-time audio processing also extends to virtual reality and augmented reality applications, where low-latency audio is essential for creating convincing and engaging environments.
In conclusion, MelCap represents a significant advancement in audio compression technology. Its unified, single-codebook approach offers a powerful and efficient solution for high-fidelity audio compression, with wide-ranging applications in music and audio production. As the technology continues to evolve, it has the potential to transform the way we create, share, and experience audio. Read the original research paper here.

