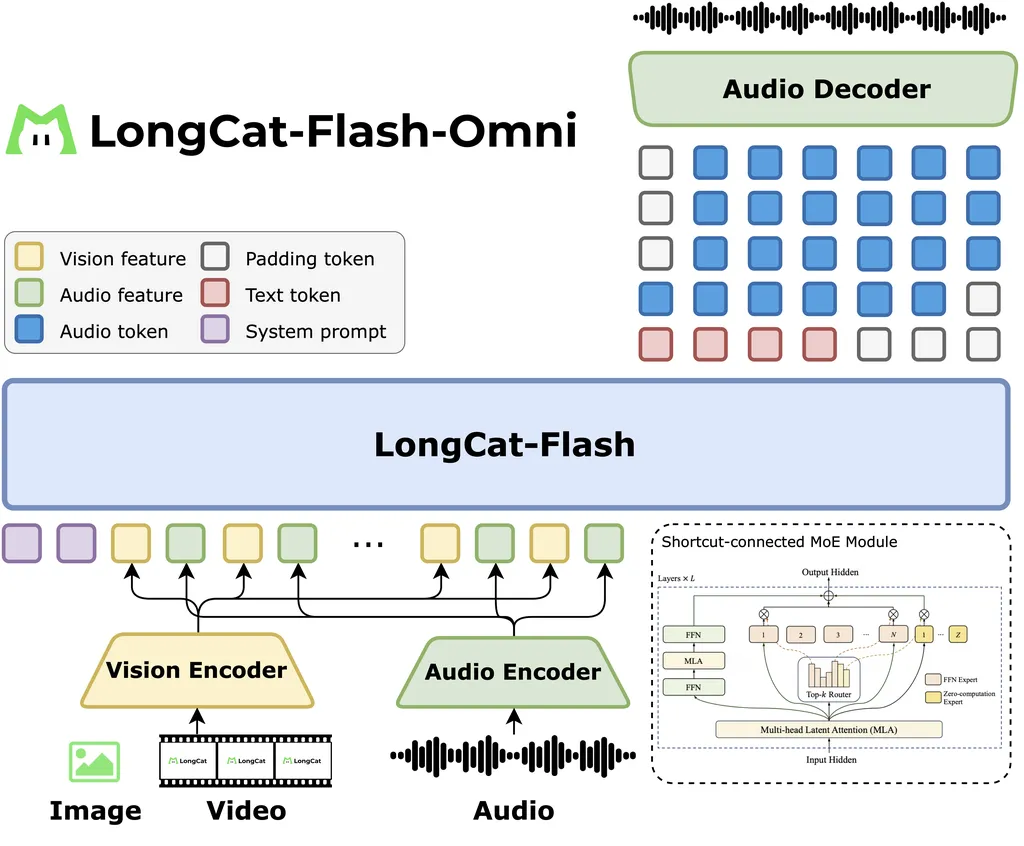
The Meituan LongCat Team has unveiled LongCat-Flash-Omni, a cutting-edge, open-source omni-modal model that’s setting new standards in real-time audio-visual interaction. This behemoth of a model boasts an impressive 560 billion parameters, with a mere 27 billion activated at any given time. The team’s innovative approach involves a curriculum-inspired progressive training strategy, which gradually introduces the model to more complex modality sequence modeling tasks. This method ensures that LongCat-Flash-Omni maintains strong unimodal capabilities while also excelling in multimodal tasks.
Building on the foundation of LongCat-Flash, which employs a high-performance Shortcut-connected Mixture-of-Experts (MoE) architecture with zero-computation experts, LongCat-Flash-Omni integrates efficient multimodal perception and speech reconstruction modules. Despite its massive size, the model achieves low-latency real-time audio-visual interaction, a feat that underscores the team’s commitment to pushing the boundaries of what’s possible in the field of multimodal AI.
To tackle the challenges posed by large-scale multimodal training, the researchers developed a modality-decoupled parallelism scheme. This approach is specifically designed to manage the data and model heterogeneity inherent in such training processes. The result is an impressive efficiency, with the model sustaining over 90% of the throughput achieved by text-only training.
Extensive evaluations have shown that LongCat-Flash-Omni achieves state-of-the-art performance on omni-modal benchmarks among open-source models. Moreover, it delivers highly competitive results across a wide range of modality-specific tasks, including text, image, video, and audio understanding and generation. The team has provided a comprehensive overview of the model architecture design, training procedures, and data strategies, and has open-sourced the model to foster future research and development in the community.
This groundbreaking work has significant implications for the music and audio industry. The ability to seamlessly integrate and interpret multiple modalities of data in real-time opens up new possibilities for interactive music production, immersive audio experiences, and advanced audio-visual content creation. As the industry continues to evolve, models like LongCat-Flash-Omni will undoubtedly play a pivotal role in shaping the future of audio technology.