In the rapidly evolving world of artificial intelligence, the quest for models that are both powerful and efficient is never-ending. Enter LFM2, a family of Liquid Foundation Models that are designed to strike a balance between these two seemingly contradictory goals. Developed by a team of researchers led by Alexander Amini and Daniela Rus, LFM2 is a testament to the potential of hardware-in-the-loop architecture search.
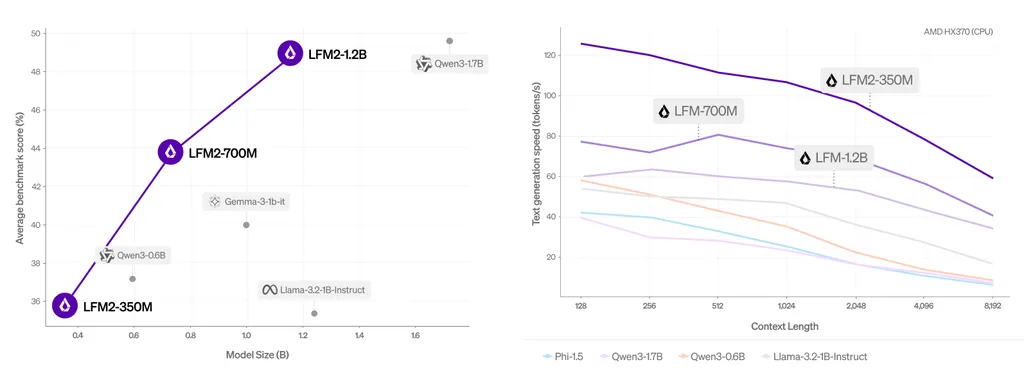
LFM2’s compact hybrid backbone is a marvel of engineering, combining gated short convolutions with a small number of grouped query attention blocks. This design choice allows LFM2 to deliver up to 2x faster prefill and decode on CPUs compared to similarly sized models. The LFM2 family covers a wide range of parameters, from 350M to 8.3B, including dense models and a mixture-of-experts variant, all with a 32K context length.
The training pipeline of LFM2 is as innovative as its architecture. It includes a tempered, decoupled Top-K knowledge distillation objective that avoids support mismatch, curriculum learning with difficulty-ordered data, and a three-stage post-training recipe of supervised fine-tuning, length-normalized preference optimization, and model merging. Pre-trained on 10-12T tokens, LFM2 models achieve strong results across diverse benchmarks, with LFM2-2.6B reaching 79.56% on IFEval and 82.41% on GSM8K.
But LFM2’s capabilities don’t stop at text. The researchers have also built multimodal and retrieval variants of LFM2. LFM2-VL is designed for vision-language tasks, LFM2-Audio for speech, and LFM2-ColBERT for retrieval. LFM2-VL supports tunable accuracy-latency tradeoffs via token-efficient visual processing, while LFM2-Audio separates audio input and output pathways to enable real-time speech-to-speech interaction competitive with models 3x larger. LFM2-ColBERT provides a low-latency encoder for queries and documents, enabling high-performance retrieval across multiple languages.
All LFM2 models are released with open weights and deployment packages for ExecuTorch, llama.cpp, and vLLM, making them a practical base for edge applications that need fast, memory-efficient inference and strong task capabilities. In a world where AI is increasingly becoming a part of our daily lives, LFM2 is a significant step towards making AI more accessible and efficient.

