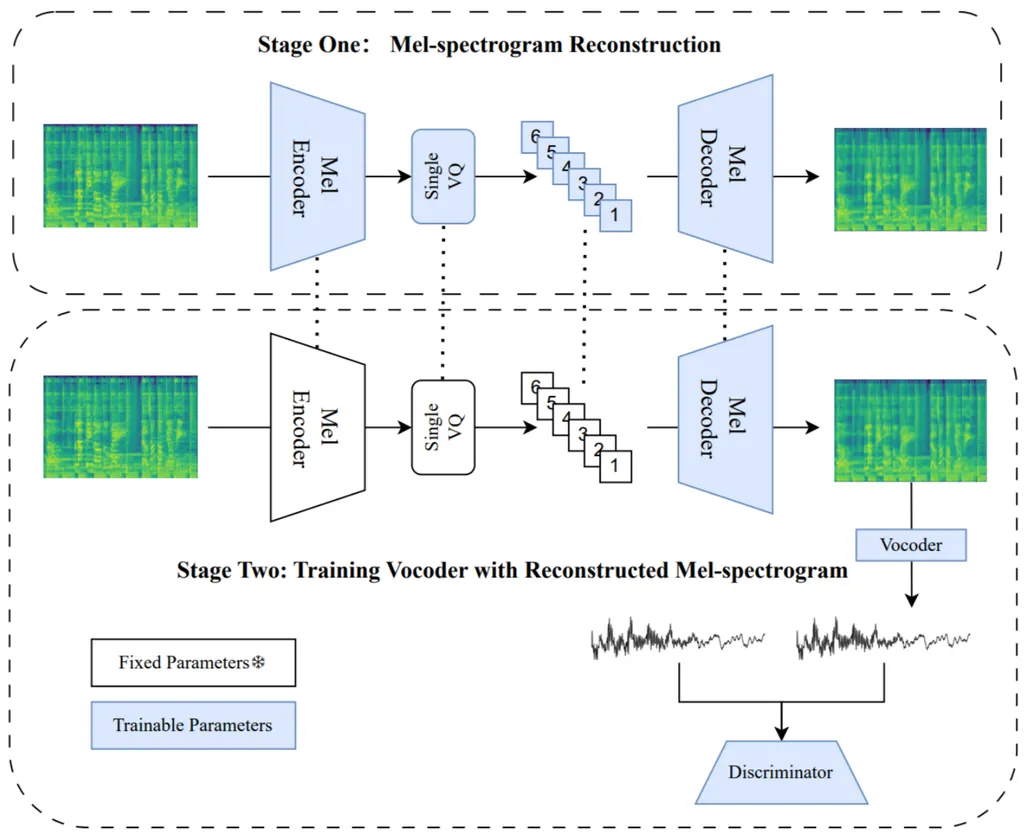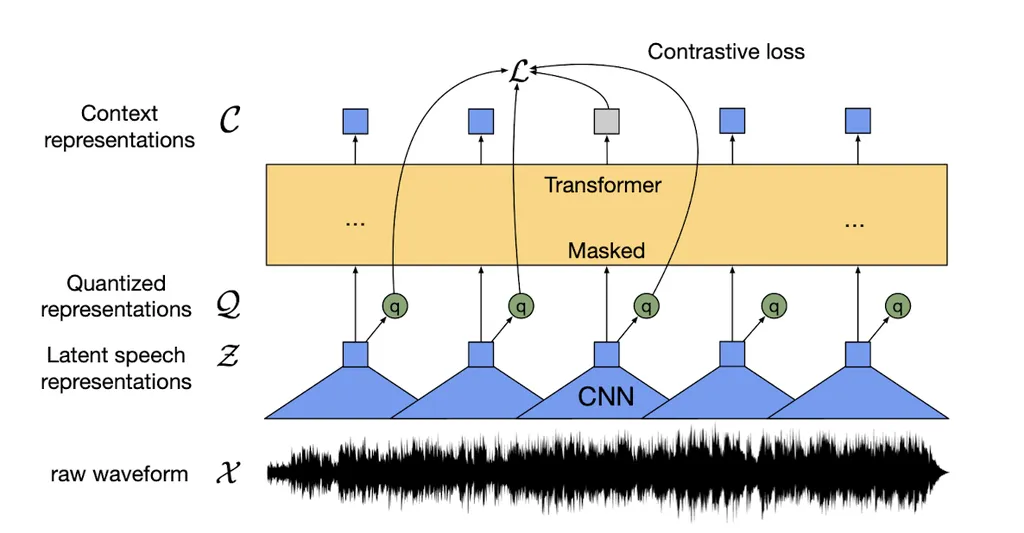
In the rapidly evolving landscape of speech processing, a groundbreaking development has emerged that promises to revolutionize the way we handle and manipulate audio data. Researchers Wei-Cheng Tseng and David Harwath have introduced Codec2Vec, a novel framework for speech representation learning that leverages the power of neural audio codecs. This innovative approach not only enhances audio compression and speech synthesis but also opens up new possibilities for a wide array of speech processing tasks.
Codec2Vec stands out by relying exclusively on discrete audio codec units, a departure from traditional methods that depend on continuous inputs. This shift brings several significant advantages. Firstly, it improves data storage and transmission efficiency, a critical factor in today’s data-driven world. Secondly, it accelerates the training process, making it faster and more streamlined. Lastly, it enhances data privacy, an increasingly important consideration in an era where data security is paramount.
The researchers explored various masked prediction strategies to derive training targets, thoroughly evaluating the effectiveness of the Codec2Vec framework. The results were impressive. When tested on the SUPERB benchmark, a comprehensive evaluation suite for speech processing tasks, Codec2Vec demonstrated competitive performance compared to continuous-input models. Notably, it achieved this while reducing storage requirements by up to 16.5 times and cutting training time by 2.3 times. These figures underscore the scalability and efficiency of the Codec2Vec framework.
The implications of this research are far-reaching. By enabling more efficient and effective speech representation learning, Codec2Vec could pave the way for advancements in areas such as speech recognition, translation, and synthesis. It could also enhance applications that rely on real-time speech processing, such as virtual assistants and language learning tools. As the technology continues to evolve, we can expect to see even more innovative uses emerge, further solidifying the role of neural audio codecs in the future of speech processing.