Neural Audio Synthesis (NAS) models have opened up exciting possibilities for interactive musical control over high-quality audio generators. However, the high latency often associated with these models has been a significant barrier to their use in real-time musical applications. A team of researchers from Queen Mary University of London and the University of Nottingham has been investigating the sources of latency and jitter in interactive NAS models and exploring ways to optimize them for low-latency inference.
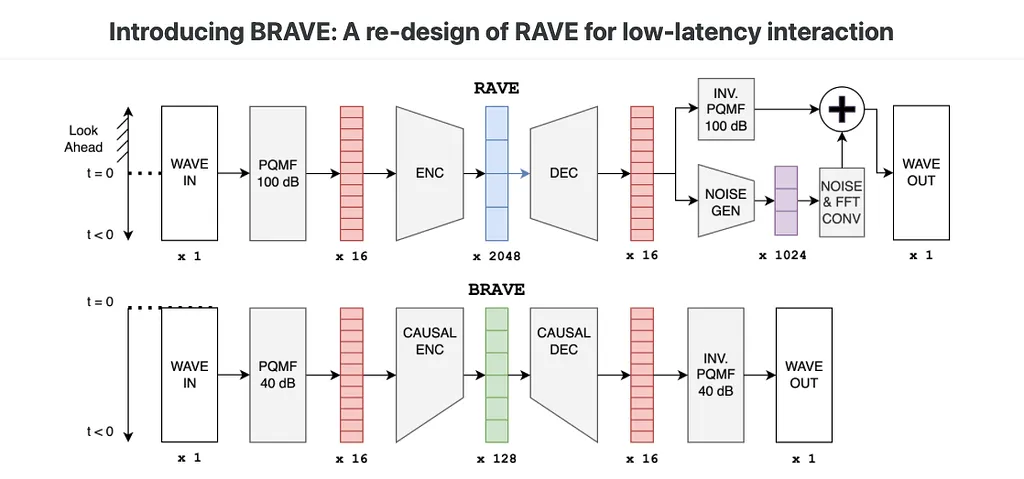
The team’s analysis of the impact of architectural choices in deep learning models on audio latency has revealed several key insights. They applied this analysis to the task of timbre transfer using RAVE, a convolutional variational autoencoder for audio waveforms introduced by Caillon et al. in 2021. By iterating on the design of the model, they were able to create BRAVE (Bravely Realtime Audio Variational autoEncoder), a low-latency model that exhibits better pitch and loudness replication while maintaining timbre modification capabilities similar to RAVE.
To ensure that BRAVE could be used in real-world musical applications, the team implemented it in a specialized inference framework for low-latency, real-time inference. They also presented a proof-of-concept audio plugin compatible with audio signals from musical instruments. The researchers hope that the challenges and guidelines they have described in their work will support other NAS researchers in designing models for low-latency inference from the ground up, enriching the landscape of possibilities for musicians.
The development of low-latency NAS models has the potential to revolutionize the way that musicians interact with audio synthesis technology. By enabling real-time control over high-quality audio generators, these models could open up new avenues for musical expression and creativity. As the field of NAS continues to evolve, it will be exciting to see how researchers build on the work of this team to create even more sophisticated and musically useful models.

