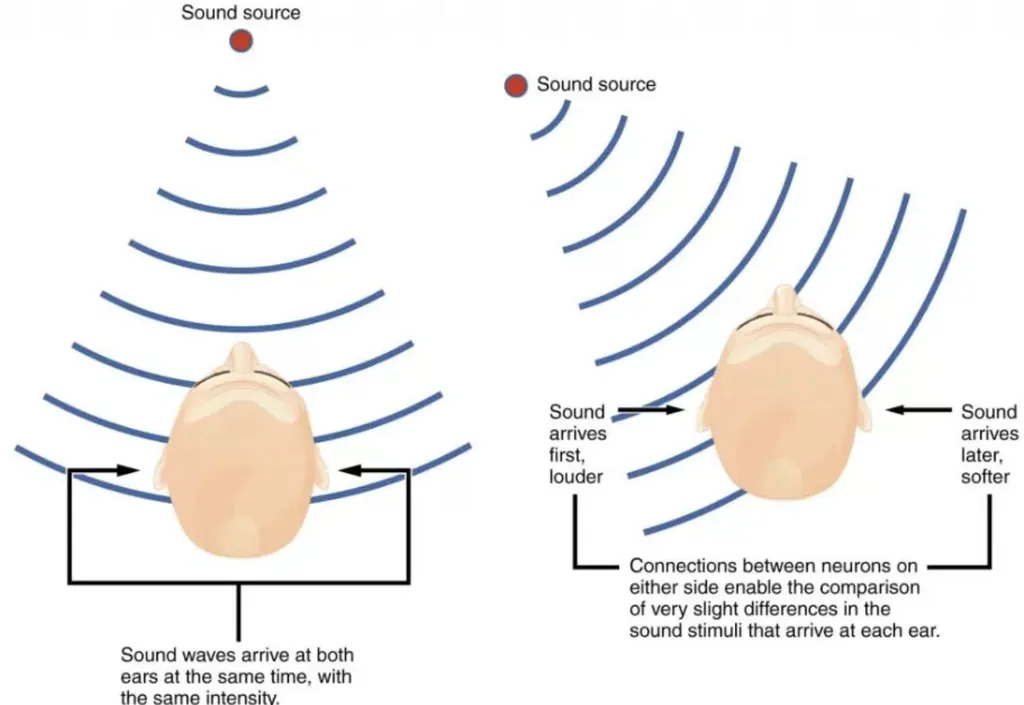
In the realm of audio technology, the ability to accurately localize sound sources is a critical challenge, particularly in the development of immersive audio experiences and advanced hearing aids. A recent study by Davoud Shariat Panah, Alessandro Ragano, Dan Barry, Jan Skoglund, and Andrew Hines delves into the intricacies of binaural sound source localization (SSL), offering valuable insights into the role of time-frequency feature design in enhancing model performance. The research, which focuses on the interplay between amplitude-based and phase-based features, provides a systematic evaluation that could significantly influence future developments in audio processing and spatial audio applications.
The study investigates the performance of a convolutional neural network (CNN) model using various combinations of amplitude-based features, such as the magnitude spectrogram and interaural level difference (ILD), and phase-based features, including the phase spectrogram and interaural phase difference (IPD). The researchers found that the choice of feature combinations can have a profound impact on model performance, often outweighing the benefits of increased model complexity. For instance, while two-feature sets like ILD and IPD are sufficient for in-domain SSL tasks, the generalization to diverse audio content requires a more comprehensive approach, combining channel spectrograms with both ILD and IPD.
One of the key findings of the study is the importance of feature design in achieving accurate and reliable SSL. The researchers evaluated their models on both in-domain and out-of-domain data, with mismatched head-related transfer functions (HRTFs), to simulate real-world conditions. Their results indicate that carefully selected feature combinations can significantly enhance the model’s ability to generalize across different acoustic environments. This is particularly relevant for applications such as virtual reality, augmented reality, and advanced hearing aids, where the ability to accurately localize sound sources in diverse settings is crucial.
The practical implications of this research are substantial. By providing a clear framework for feature selection, the study offers valuable guidance for developers and researchers working on binaural SSL systems. The findings suggest that a low-complexity CNN model, when equipped with the optimal feature sets, can achieve competitive performance. This could lead to more efficient and effective audio processing solutions, reducing the computational resources required without compromising accuracy.
Moreover, the study underscores the importance of understanding the underlying principles of sound localization in the human auditory system. By mimicking the way humans use both amplitude and phase information to localize sound sources, the researchers have developed a model that not only performs well in controlled environments but also generalizes effectively to real-world scenarios. This bio-inspired approach could pave the way for more sophisticated and intuitive audio technologies, enhancing the user experience in various applications.
In conclusion, the systematic evaluation of time-frequency features for binaural sound source localization presented in this study offers a significant contribution to the field of audio technology. By highlighting the importance of feature design and providing practical insights into model performance, the research sets a new standard for the development of advanced SSL systems. As the demand for immersive and spatially aware audio experiences continues to grow, the findings of this study will be invaluable in shaping the future of audio processing and spatial sound applications.

