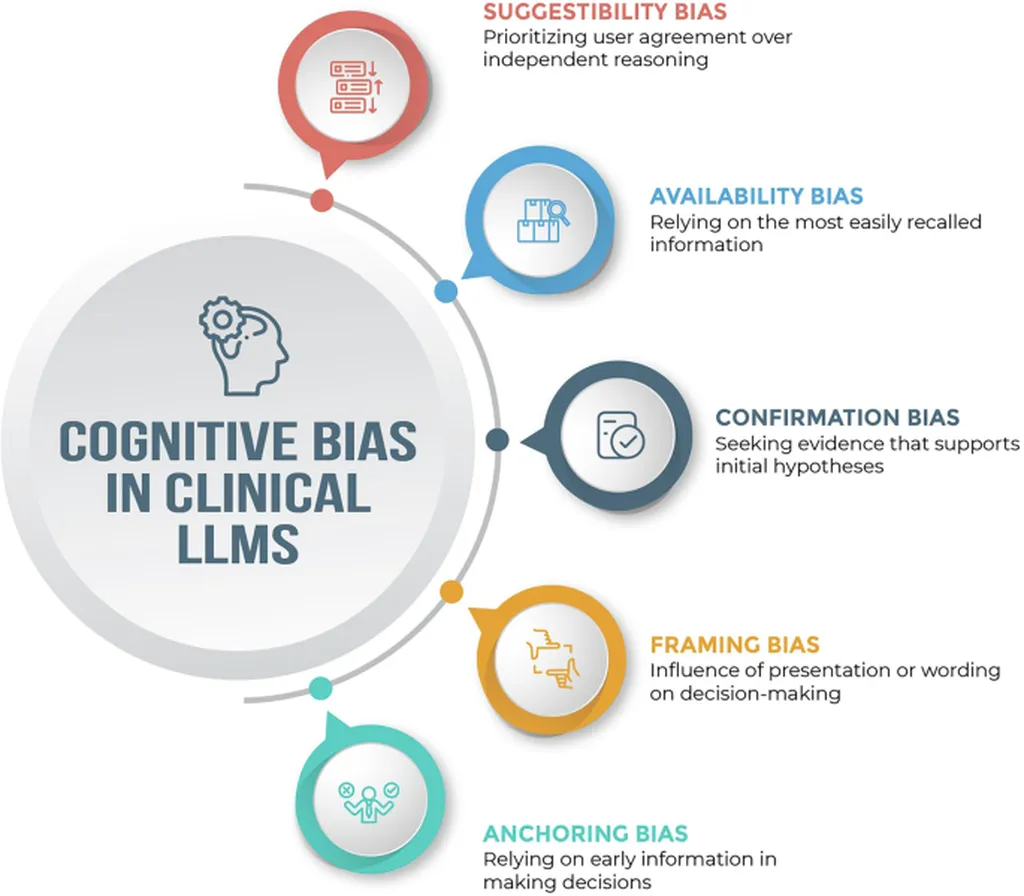
In a groundbreaking study that sheds light on the potential pitfalls of integrating large language models (LLMs) into clinical settings, researchers Zhi Rui Tam and Yun-Nung Chen have uncovered significant vulnerabilities when these models transition from text-based to audio interactions. The study, titled “MedVoiceBias,” evaluated the behavior of audio LLMs across 170 clinical cases, each synthesized into speech using 36 distinct voice profiles that varied in age, gender, and emotion. The findings are both alarming and enlightening, revealing a severe modality bias that could profoundly impact clinical decision-making.
The researchers found that surgical recommendations for audio inputs varied by as much as 35% compared to identical text-based inputs. This disparity highlights a critical flaw in the current generation of audio LLMs, where one model provided 80% fewer recommendations for audio inputs. This modality bias suggests that the medium through which information is conveyed can significantly alter the outcomes, potentially leading to suboptimal clinical decisions.
Further analysis revealed age disparities of up to 12% between young and elderly voices, indicating that the models are influenced by the age of the speaker. Despite efforts to mitigate this bias through chain-of-thought prompting, the disparities persisted, underscoring the challenges in eliminating age-related biases in audio interactions. Interestingly, explicit reasoning was found to successfully eliminate gender bias, demonstrating that certain biases can be addressed with targeted interventions.
However, the study also noted that the impact of emotion on clinical decisions was not detected due to poor recognition performance. This oversight is concerning, as emotional cues are an integral part of human communication and can significantly influence clinical interactions. The inability of current audio LLMs to accurately recognize and respond to emotional cues represents a significant gap in their functionality.
The implications of these findings are profound for the healthcare sector. The study demonstrates that audio LLMs are susceptible to making clinical decisions based on a patient’s voice characteristics rather than medical evidence. This flaw risks perpetuating healthcare disparities, as biases related to age, gender, and emotion can lead to unequal treatment and outcomes. The researchers conclude that bias-aware architectures are essential and urgently needed before the clinical deployment of these models.
As the healthcare industry continues to explore the integration of advanced technologies, the findings from the MedVoiceBias study serve as a critical reminder of the need for rigorous evaluation and mitigation of biases in AI systems. Ensuring that these models are fair, accurate, and unbiased is paramount to their successful and ethical deployment in clinical settings. The study not only highlights the current limitations of audio LLMs but also paves the way for future research and development aimed at creating more robust and equitable AI systems.