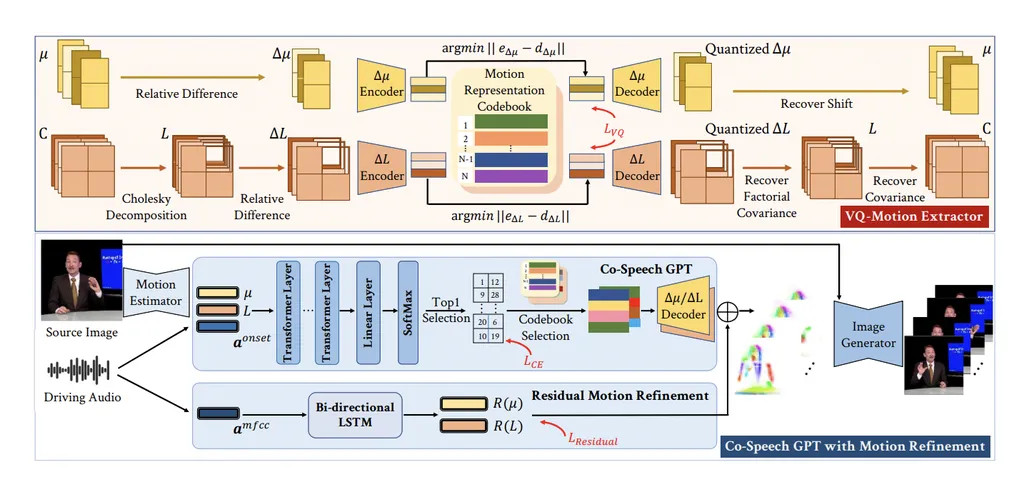
Creating natural and synchronized co-speech gesture videos has always been a tough nut to crack in the world of audio and video synthesis. Recent advancements have seen the use of motion graphs to tap into the potential of existing video data. However, the many-to-many relationship between audio and gestures has posed a challenge, as previous methods relied on one-to-one mapping.
Enter Yafei Song, Peng Zhang, and Bang Zhang, who have proposed a novel framework to tackle this issue. Their approach starts with a diffusion model that generates gesture motions. This model implicitly learns the joint distribution of audio and motion, allowing it to create contextually appropriate gestures from input audio sequences. The researchers have also enriched the training process of the diffusion model by extracting both low-level and high-level features from the input audio.
But the innovation doesn’t stop there. The team has designed a motion-based retrieval algorithm that identifies the most suitable path within the graph by assessing both global and local similarities in motion. This is particularly useful as not all nodes in the retrieved path are sequentially continuous. To ensure a smooth output, the final step involves seamlessly stitching together these segments to produce a coherent video.
The results of their experiments speak volumes about the efficacy of their proposed method. It has shown significant improvement over prior approaches in terms of synchronization accuracy and the naturalness of generated gestures. This research is a significant step forward in the realm of co-speech gesture video generation, and it will be exciting to see how this technology evolves in the future.

