Text-based talking-head video editing is a fascinating frontier in the world of audio and video technology. Imagine being able to edit a talking video as easily as you would edit a text document. This is the goal of a recent research paper by Bo Han, Heqing Zou, Haoyang Li, Guangcong Wang, and Chng Eng Siong. The team aims to make it possible to insert, delete, and substitute segments of talking videos through a user-friendly text editing approach.
However, this task is fraught with challenges. The first is the need for a generalizable talking-face representation. This means that the system should be able to understand and replicate the nuances of different people’s facial expressions and speech patterns. The second challenge is ensuring seamless audio-visual transitions. This is crucial for maintaining the viewer’s immersion and the video’s overall quality. The third challenge is preserving the identity of the talking face. The system should be able to edit the video without altering the person’s unique facial features.
Previous attempts to tackle these challenges have had limited success. Some methods require extensive training data and expensive test-time optimization, making them impractical for real-world use. Others directly generate a video sequence without considering in-context information, leading to poor generalizable representation, incoherent transitions, or inconsistent identity.
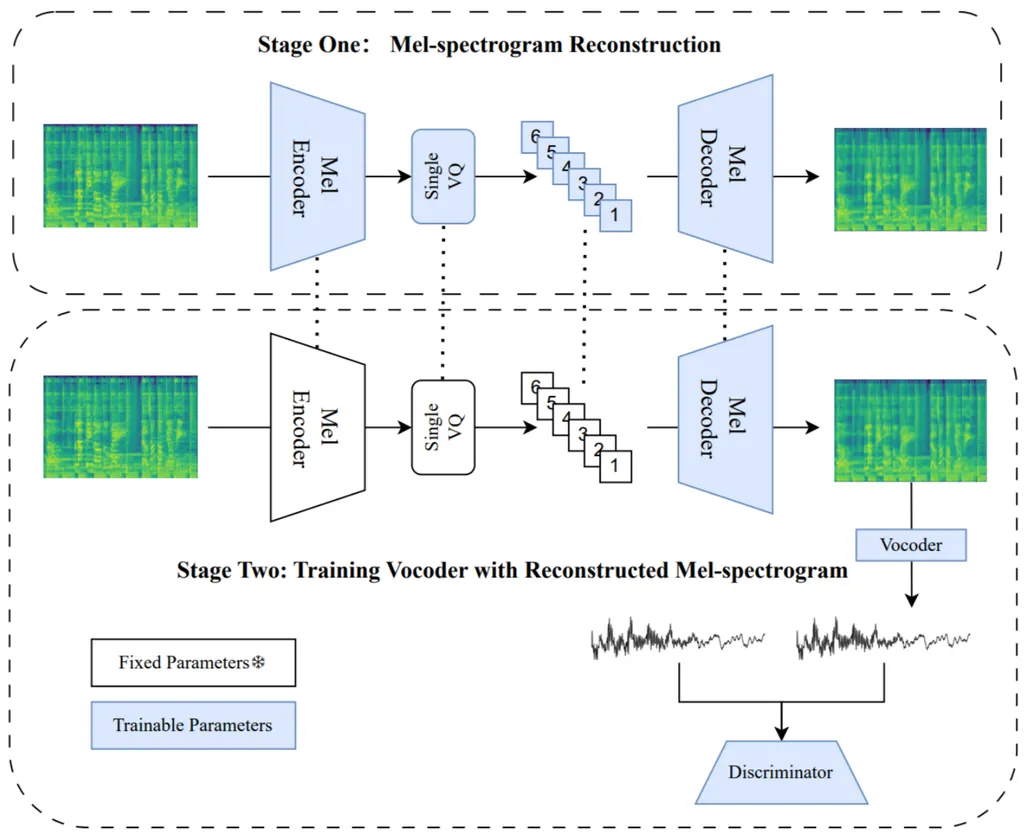
The researchers propose an efficient cascaded conditional diffusion-based framework to address these issues. This framework consists of two stages: audio to dense-landmark motion and motion to video. In the first stage, they introduce a dynamic weighted in-context diffusion module. This module synthesizes dense-landmark motions given an edited audio, effectively capturing the subtle movements of the face during speech.
In the second stage, they present a warping-guided conditional diffusion module. This module first interpolates between the start and end frames of the editing interval to generate smooth intermediate frames. Then, with the help of the audio-to-dense motion images, these intermediate frames are warped to obtain coarse intermediate frames. A diffusion model is then used to generate detailed and high-resolution target frames, ensuring coherent and identity-preserved transitions.
The cascaded conditional diffusion model decomposes the complex talking editing task into two flexible generation tasks. This approach provides a generalizable talking-face representation, seamless audio-visual transitions, and identity-preserved faces, even with a small dataset. The researchers’ experiments have shown the effectiveness and superiority of their proposed method.
This research could significantly impact the music and audio industry. Imagine being able to easily edit music videos, interviews, or live performances. This technology could also revolutionize video conferencing, making it possible to edit and enhance our virtual interactions in real-time. The potential applications are vast, and we can’t wait to see how this technology evolves.