In the rapidly evolving landscape of artificial intelligence, the demand for efficient data processing and model optimization is more critical than ever. Researchers Rongmei Liang, Zizheng Liu, Xiaofei Wu, and Jingwen Tu have taken a significant step forward in addressing these needs with their work on Combined Regularized Support Vector Machines (CR-SVMs). Their research, published in the journal “Parallel Computing,” introduces a unified optimization framework based on a consensus structure that promises to revolutionize how we handle distributed-stored big data.
CR-SVMs are powerful tools for managing structural information among data features, but their potential has been hampered by the lack of efficient algorithms for large-scale, distributed data. The researchers’ new framework is a game-changer, offering versatility and scalability. It supports various loss functions and combined regularization terms and can be extended to non-convex regularization terms, making it a robust solution for a wide range of applications.
To bring this framework to life, the team developed a distributed parallel alternating direction method of multipliers (ADMM) algorithm. This algorithm enables efficient computation of CR-SVMs even when data is stored in a distributed manner. To ensure the algorithm’s convergence, the researchers introduced the Gaussian back-substitution method, further enhancing its reliability.
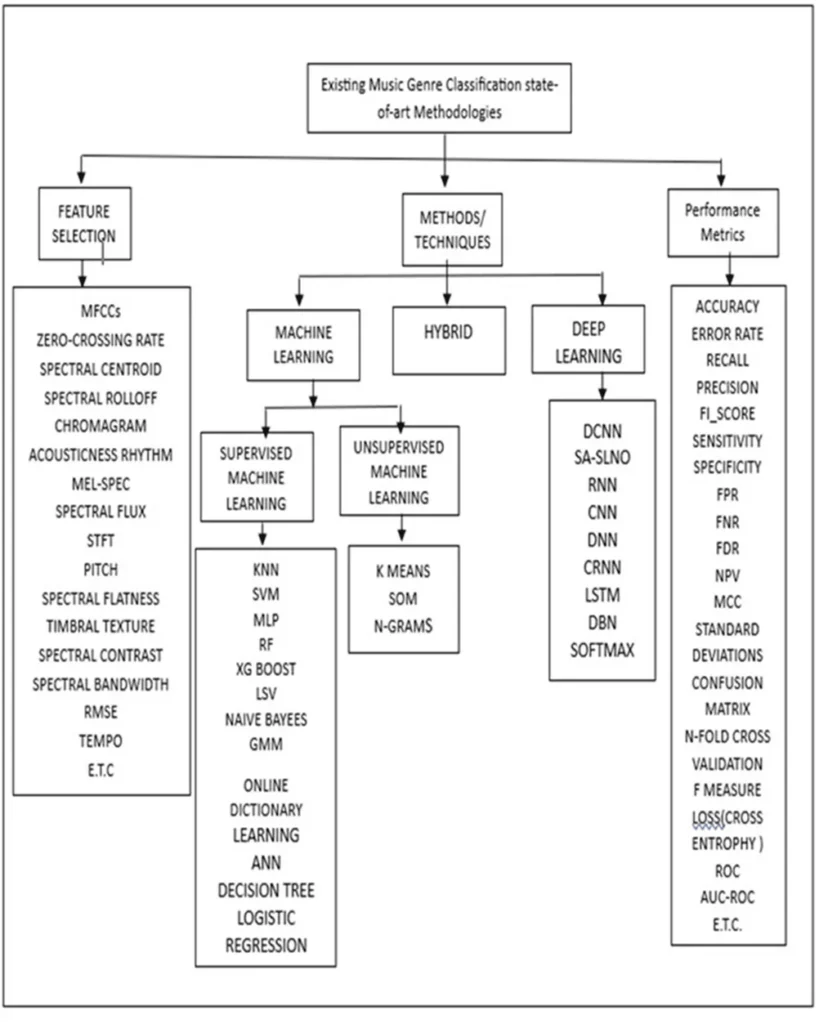
One of the most exciting applications of this research is in music information retrieval. The team introduced a new model, the sparse group lasso support vector machine (SGL-SVM), and applied it to music genre classification. This application demonstrates the practical potential of their work, showcasing how advanced algorithms can be used to organize and retrieve music data more effectively.
Theoretical analysis confirms that the computational complexity of the proposed algorithm remains unaffected by different regularization terms and loss functions. This universality highlights the algorithm’s robustness and adaptability, making it a valuable tool for researchers and practitioners alike.
Experiments conducted on synthetic and free music archiv datasets further validate the algorithm’s reliability, stability, and efficiency. These results underscore the practical benefits of the researchers’ work and pave the way for future advancements in music genre classification and beyond.
In summary, the research by Liang, Liu, Wu, and Tu represents a significant leap forward in the field of AI and data processing. Their unified optimization framework and distributed parallel ADMM algorithm offer a versatile and scalable solution for handling big data, with promising applications in music information retrieval and other domains. As we continue to explore the potential of artificial intelligence, this work serves as a testament to the power of innovative algorithms and the transformative impact they can have on our world.

